

Demo video
Click here for a discussion and demo of this Generative AI Web Browser on my channel on YouTube
Introduction
There is an ongoing arms race in tech world of the internet waged between the users and the ad companies who are constantly trying to garner the users attention. This war has been mostly been fought by using adblockers, which are essentially lists of known advertising websites whose content is stripped from the pages we view. However as we have seen in recent times there is a constant push back from sites attempting to detect these adblockers and in some cases to even stop the functionality of the website until the user consumes ads.
This is only the start of it though, we also have content being hidden under layers of meaningless padding, repeated content, constantly regurgitated in hundreds of subtle different ways while essentially saying the same thing. Click bait sites or articles that are only designed to gather interaction from the users. Or even more subtle things such as advertisements disguised as real content.
The modern web is a mess.
How do we fix the Internet?
So how can we fix this? Well with modern advances in LLMs and AI in general it is actually quite simple. We no longer consume the internet, we allow an AI to consume it on our behalf and then present a cleaned up version of the internet back to us. This new clean internet would now have no advertisements, no click-bait, no meaningless content. It would be back to how the internet was originally supposed to be.
Why big tech won’t build this
The large tech companies would never build this though, why would Google build a browser that would essentially rob them of their main source of income. Why would any of the large companies build it? There are numerous reasons for this, not only is it disruptive to their current revenue models, but it would also disrupt much of the tracking and data gathering that the current internet provides. No internet company would want this as drying up the advertising revenue stream would never be considered.
So why don’t we build it…
To start with we need access to a LLM, you can take your pick as they all have their pros and cons. For the sake of this blog post we will talk about using one in Amazon Bedrock, but if you prefer your own LLM by all means swap it out.
The general architecture is going to look something like this:
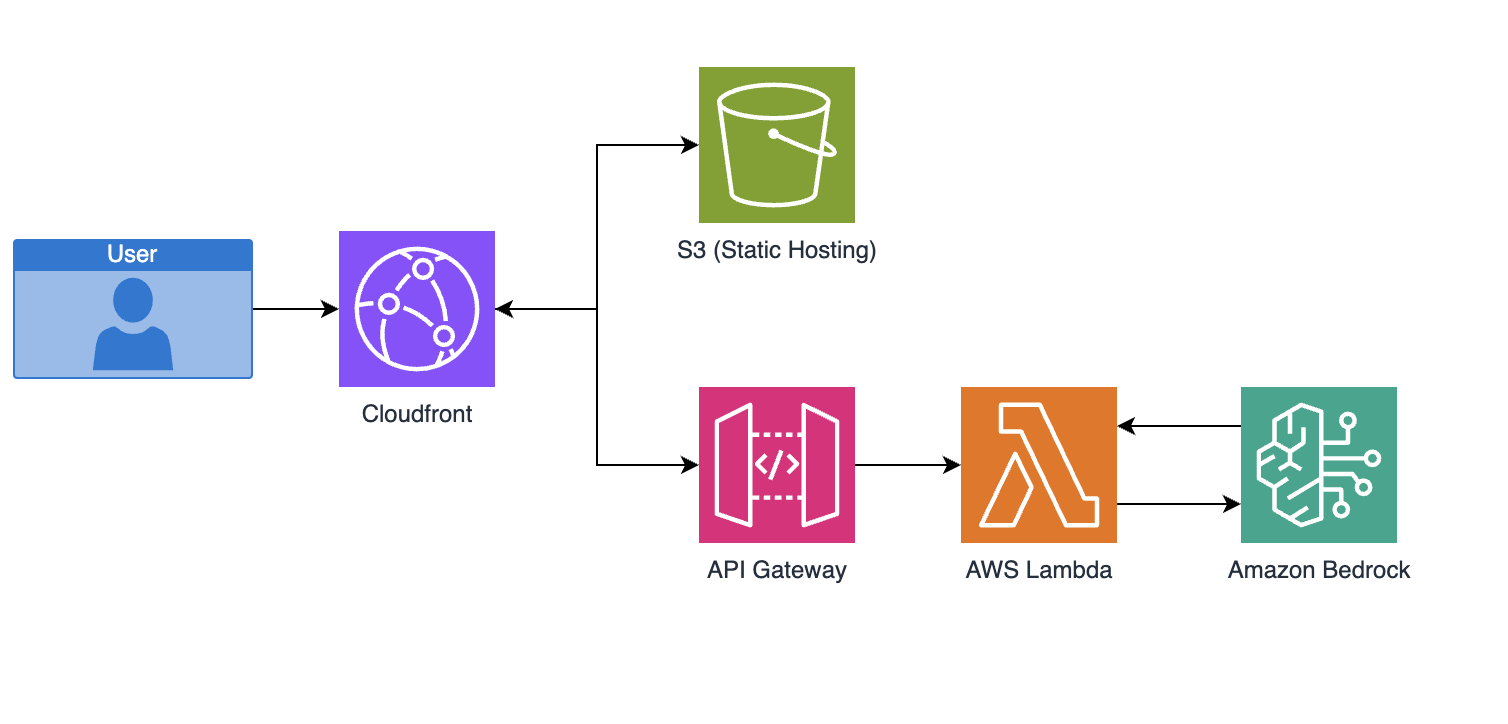
The front end is a very simple react application that simply has a browser style address bar and a go button. It sends the request to the API Gateway. Its so simple I can actually put the example code in line here (its not very exciting for this POC):
import React, { useState } from 'react';
import './App.css';
function App() {
const [url, setUrl] = useState('');
const [content, setContent] = useState('');
const [loading, setLoading] = useState(false);
const handleGo = async () => {
setLoading(true);
try {
const response = await fetch('http://your-api-gw-url, {
method: 'POST',
headers: {
'Content-Type': 'application/json',
},
body: JSON.stringify({ url }),
});
if (response.ok) {
const html = await response.text();
setContent(html);
} else {
setContent('Error fetching content.');
}
} catch (error) {
console.error('Error fetching content:', error);
setContent('Error fetching content.');
} finally {
setLoading(false);
}
};
return (
<div className="App">
<header className="App-header">
<input
type="text"
value={url}
onChange={(e) => setUrl(e.target.value)}
placeholder="Enter URL"
/>
<button onClick={handleGo}>Go</button>
</header>
<div className="App-content-wrapper">
{loading ? (
<div className="spinner-container">
<div className="spinner"></div>
<div className="spinner-text">Loading...</div>
</div>
) : (
<div className="App-content" dangerouslySetInnerHTML=></div>
)}
</div>
</div>
);
}
export default App;
The Lambda function will then use puppeteer to fully render the webpage, ads and all, and extracts the raw HTML content. Setting up puppeteer to run within lambda is a blog post in itself, so I would suggest you read one of the many other examples of how to do this as I won’t go into it here.
The code that we run will look something like this snippet:
const browser = await puppeteer.launch({ headless: true });
const page = await browser.newPage();
await page.goto(url, { waitUntil: 'networkidle2' });
const html = await page.content();
await browser.close();
// Use cheerio to strip out unnecessary tags and attributes
const $ = cheerio.load(html);
$('script, style, link, meta, [srcset], [onclick]').remove();
// Remove all attributes from elements except for <img> tags
$('*').each(function() {
if (this.tagName !== 'img') {
const element = $(this);
const attributes = element.attr();
for (let attr in attributes) {
element.removeAttr(attr);
}
}
});
const cleanedHtml = $.html();
Where we get the html content and strip out some unnecessary noise. We are doing this just due to limitations on the size of the content that we want to send to the LLM. This would not be necessary as the LLMs get bigger and more advanced.
This content is then passed to the LLMs with instructions to extract only the relevant information and any relevant images.
The prompt you can use for this will be something like this, although you may find a more comprehensive prompt will return even better results.
Given the following content, write it as a factual article. Remove any unnecessary intensifier words, adverts or clickbait. Provide the result as cleanly formatted HTML. For any images, keep the same src attribute. The response MUST only be HTML, without explanation or formatting, DO NOT include any markdown. The content is:\n\n${cleanedHtml}
The LLM returns the newly cleaned html and this is displayed in our new browser.
What does this look like in practice? Well its better to watch the video at the start of this blog, but if you just want to see:
Before:
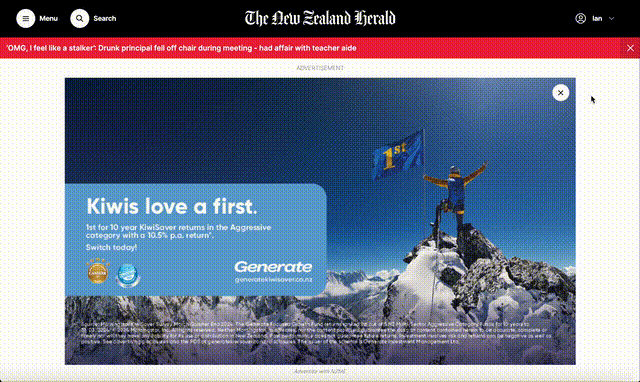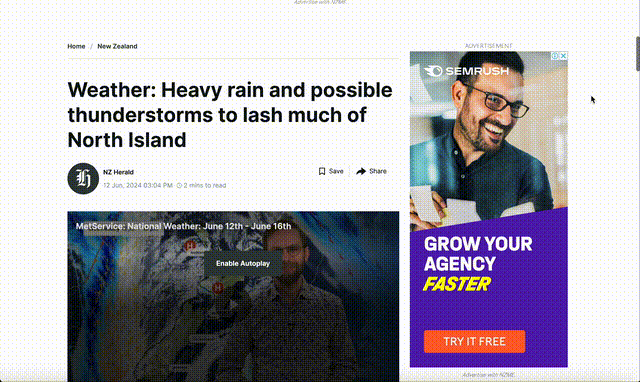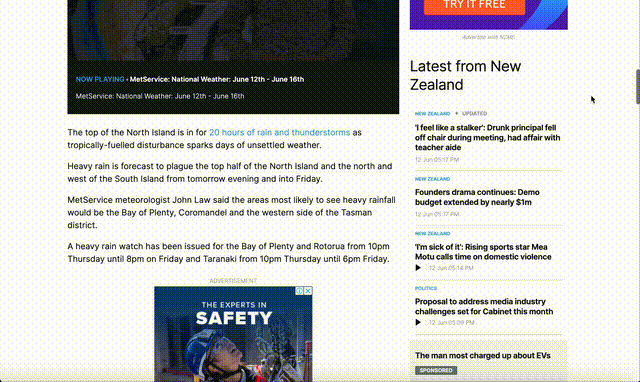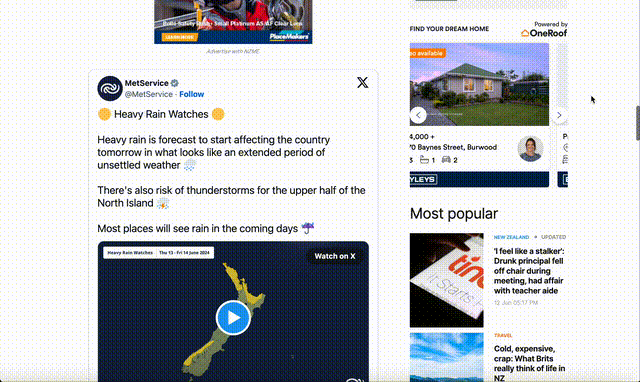
After:
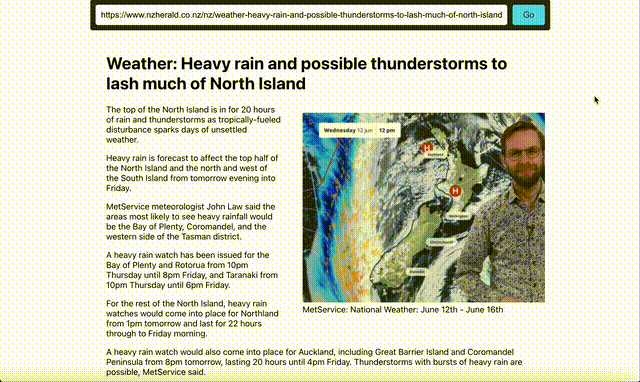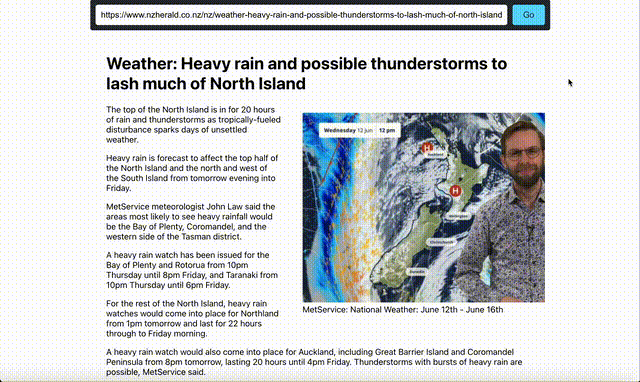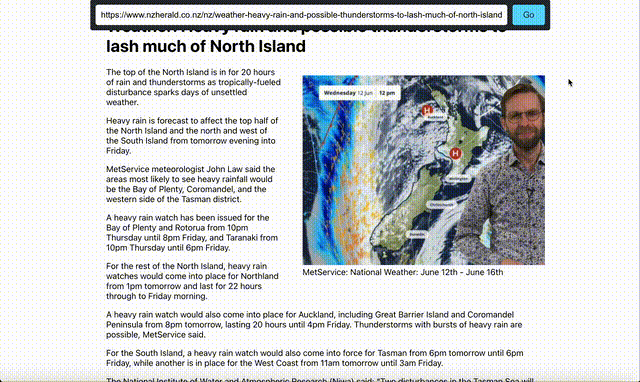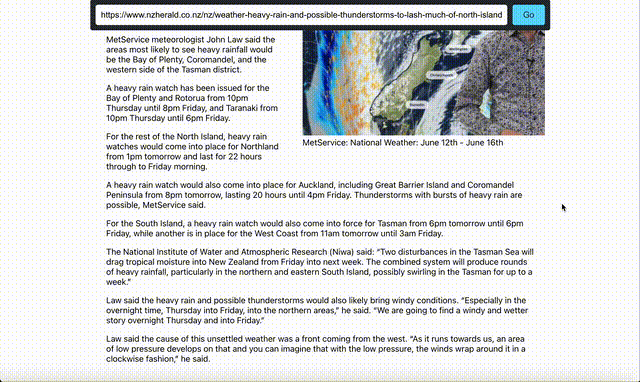
This news page has been cleaned up to just return the content. Its important to note that this works for any website and any content, because the LLM is “understanding” the content it doesnt matter what you give it, it will just clean it up. If we want to expand on this we would add more context to the LLM, and probably even train it to better understand websites. Of course the beauty of solutions like this is that you dont have to train it, you dont ahve to do any of the heavy lifting anymore, you can just use it.
So there we have it, a new browser for the current internet, that no big tech company would build.
Final Thoughts
Where is this going to lead I hear you all ask… well I believe there is going to be a new arms race of sorts. We are going to see a resurgence of the browser wars from the early 00s when you had netscape fighting with internet explorer or even chrome and Firefox, but this time it will be the war of the AI browsers. Companies will form, or most likely non profit organisations and open source solutions that will build these new browsers. Then things will get really interesting as advertising will no longer be a viable way of generating money on the internet.
Exciting times ahead.