

Enhancing Email Security with AI-Powered Spam Detection
Demo video
Introduction
In this blog post we are going to discuss how to build a Generative AI based email spam filter. Not only will we discuss this but we will also talk about how to evaluate the performance of Generative AI solutions before you invest the time in actually building them.
As I think we have all seen there is a massive increase in the number of spam and phishing attacks, not only is there an increase but there is also an increasing sophistication in the way that the attacks are being presented. While there are current methods available to try and mitigate the number of spam or phishing messages that people see, these methods are starting to fail.
The spammers are evolving at a faster or at the least a similar rate to the methods in place that are blocking them. In general most of the existing methods to block spam have been based around Machine Learning. This involves training up large models using large datasets to try and identify Spam. Although these methods have been relatively effective up until recent times, advancements in spam and the sheer volume of spam have made them less effective.
The general issue with large ML models is that they require constant updates. This never ending training and a need for new data makes them hard and expensive to maintain. Existing email providers have tried to mitigate these costs by essentially getting their users to label the spam for them, this has allowed them to build massive datasets of labeled data that they can then use to further train their ML models. This is becoming overly complex and susceptible to inaccuracies. If users mis-label spam messages the models actually become worse.
Since these ML models have started to become less efficient, there has been a push to move to more manual methods to mitigate the spam and phishing attacks. Often companies will spend large amounts of money in training programs to try and teach their staff to identify spam and phishing methods. Although this does have its place in the security posture of a company, it is not an ideal solution to handle spam. The ideal solution is to make sure that spam and phishing never reaches the users in the first place.
So how do we fix this?
Well we are proposing that using a Generative AI based solution could alleviate many of these issues.
The biggest advantage of using a GenAI solution is that there is absolutely no training required. Because the solution is relying on the AI understanding the concept of spam rather than the very binary notion of spam/not spam we can achieve a very advanced model without the significant costs associated with training a complex traditional ML model.
However, we should evaluate this assumption and perform some testing to see how a GenAI solution would actually perform.
Evaluation
To evaluate the performance of any ML model we usually want to get some statistics about how the model will perform against a large dataset. We are looking to find out the precision, recall, accuracy and F1 score of our model.
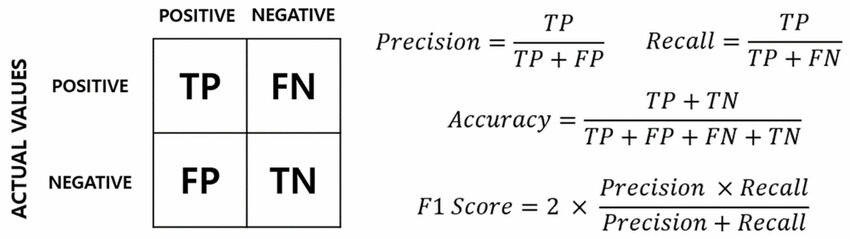
The Precision can be described as, how many of the emails classified as spam are actually spam. The Recall is how well our model can identify spam emails. The Accuracy is the overall measure of the model’s performance. Finally the F1 Score is a single metric that balances both precision and recall.
To get these metrics we are in luck, there is an evaluation tool built in to Amazon Bedrock. This allows us to configure an automatic evaluation of our GenAI models.
Building the dataset
To run this evaluation in Amazon Bedrock we need a dataset, the dataset that Amazon Bedrock expects is in a JSON line format and each line will consist of a prompt such as this:
{
"prompt": "Evaluate if this email content is likely to be spam. Provide a boolean response, where 'true' is a spam email. Respond with a SINGLE WORD, either 'true' or 'false'. Do not provide any other information.\n\nThe content is:\n\nFrom rssfeeds@jmason.org Fri Sep 27 10:40:59 2002\nReturn-Path: <rssfeeds@example.com>\nDelivered-To: yyyy@localhost.example.com\nReceived: from localhost (jalapeno [127.0.0.1])\n\tby jmason.org (Postfix) with ESMTP id 8B3FB16F16\n\tfor <jm@localhost>; Fri, 27 Sep 2002 10:40:59 +0100 (IST)\nReceived: from jalapeno [127.0.0.1]\n\tby localhost with IMAP (fetchmail-5.9.0)\n\tfor jm@localhost (single-drop); Fri, 27 Sep 2002 10:40:59 +0100 (IST)\nReceived: from dogma.slashnull.org (localhost [127.0.0.1]) by\n dogma.slashnull.org (8.11.6/8.11.6) with ESMTP id g8R80xg00774 for\n <jm@jmason.org>; Fri, 27 Sep 2002 09:00:59 +0100\nMessage-Id: <200209270800.g8R80xg00774@dogma.slashnull.org>\nTo: yyyy@example.com\nFrom: fark <rssfeeds@example.com>\nSubject: Skateboarder drives-through Subway. With his face\nDate: Fri, 27 Sep 2002 08:00:59 -0000\nContent-Type: text/plain; encoding=utf-8\nX-Spam-Status: No, hits=-292.7 required=5.0\n\ttests=AWL,T_URI_COUNT_0_1\n\tversion=2.50-cvs\nX-Spam-Level: \n\nURL: http://www.newsisfree.com/click/-5,8296987,1717/\nDate: 2002-09-27T02:45:51+01:00\n\n(DeKalb Daily Chronicle)\n\n\n",
"referenceResponse": "false"
}
This example here is taken from an old dataset of existing spam messages, shown for illustration purposes in this blog post as a more recent spam message is often much larger due to the amount of html and embedded images etc. This however raises a good point, to get our accurate response we have to make sure we are using a large amount of varied datasets to build our test set. It is also worth including a large number of modern email spam messages that have been flagged by our existing providers. It is also extremely useful to get the spam messages that were missed by modern email providers as this is really useful for testing our solution.
Amazon Bedrock automatic evaluation
To setup an evaluation job in Amazon Bedrock once we have our dataset is quite straight forward. We want to perform an automated evaluation.
To create an evaluation job, you initially need to give it a name:
Then you select your model and the type of evaluation. We want to use a question and answer type as we will have a prompt that essentially says “Is this spam?” and we expect a yes or no response as our answer.
We specify our source dataset, which contains all of the prompts that will be evaluated and their expected responses. We also need to specify a results bucket to store all of the evaluation results.
After entering these details we can execute our job.
After a fairly long time depending on the size of your dataset (think up to hours not minutes), the job will complete and you can view all of the results.
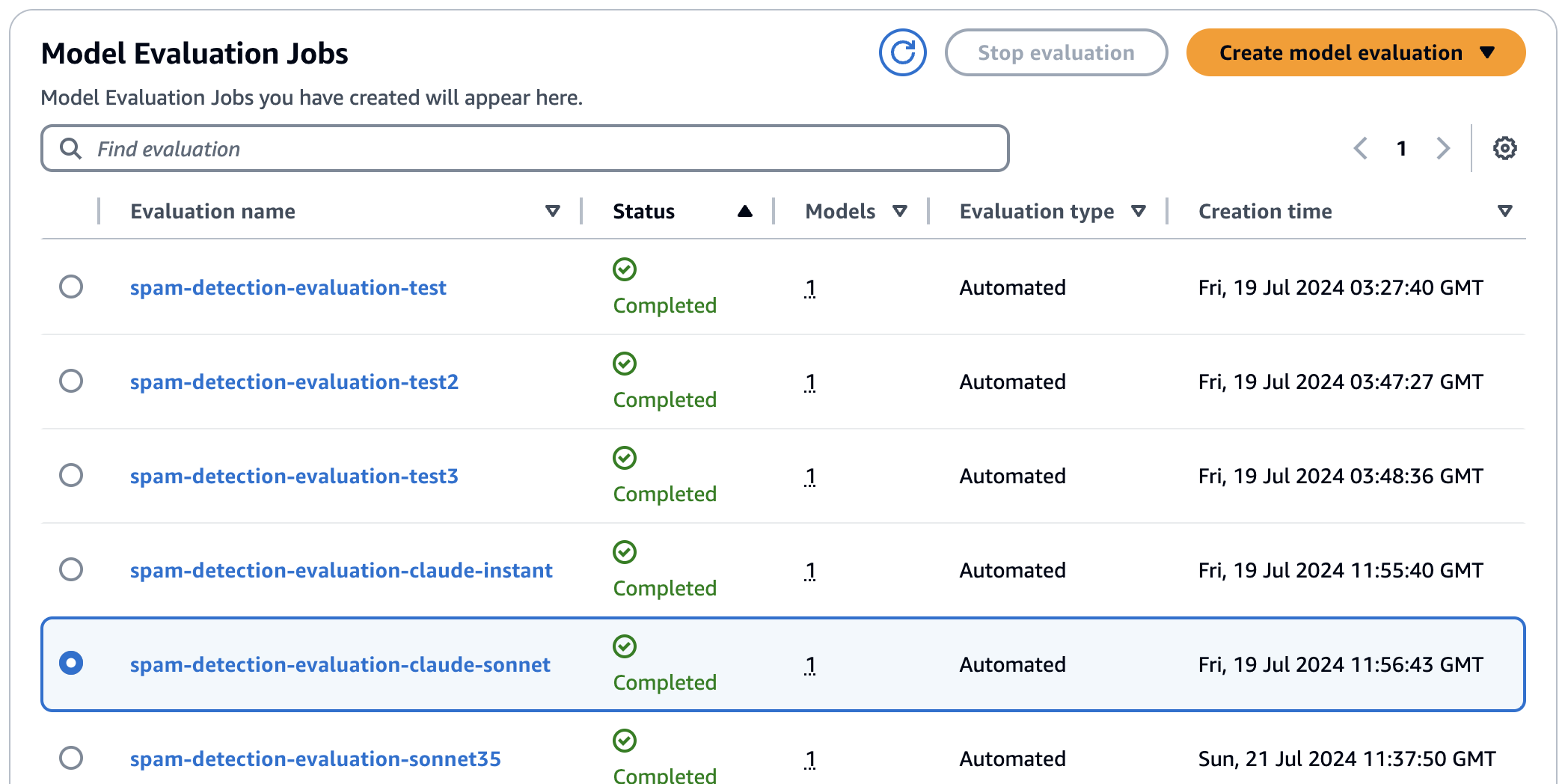
For a question and answer type of evaluation, using the Accuracy metric, we will get an F1 score directly.
The results for two different models that we evaluated are below.
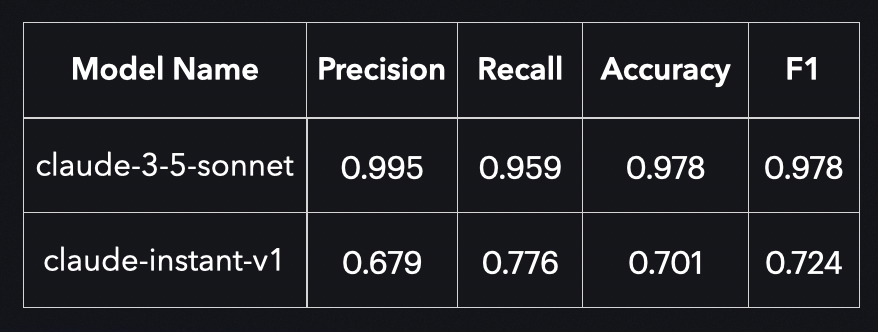
Surprisingly we are seeing that we are getting extremely high scores, this is indicating that the model is performing excellently when detecting spam. Unsurprisingly the faster and cheaper model is not performing as well.
Building a full solution in AWS
We can now build a full end to end solution in AWS. The architecture we are going to build is as follows.
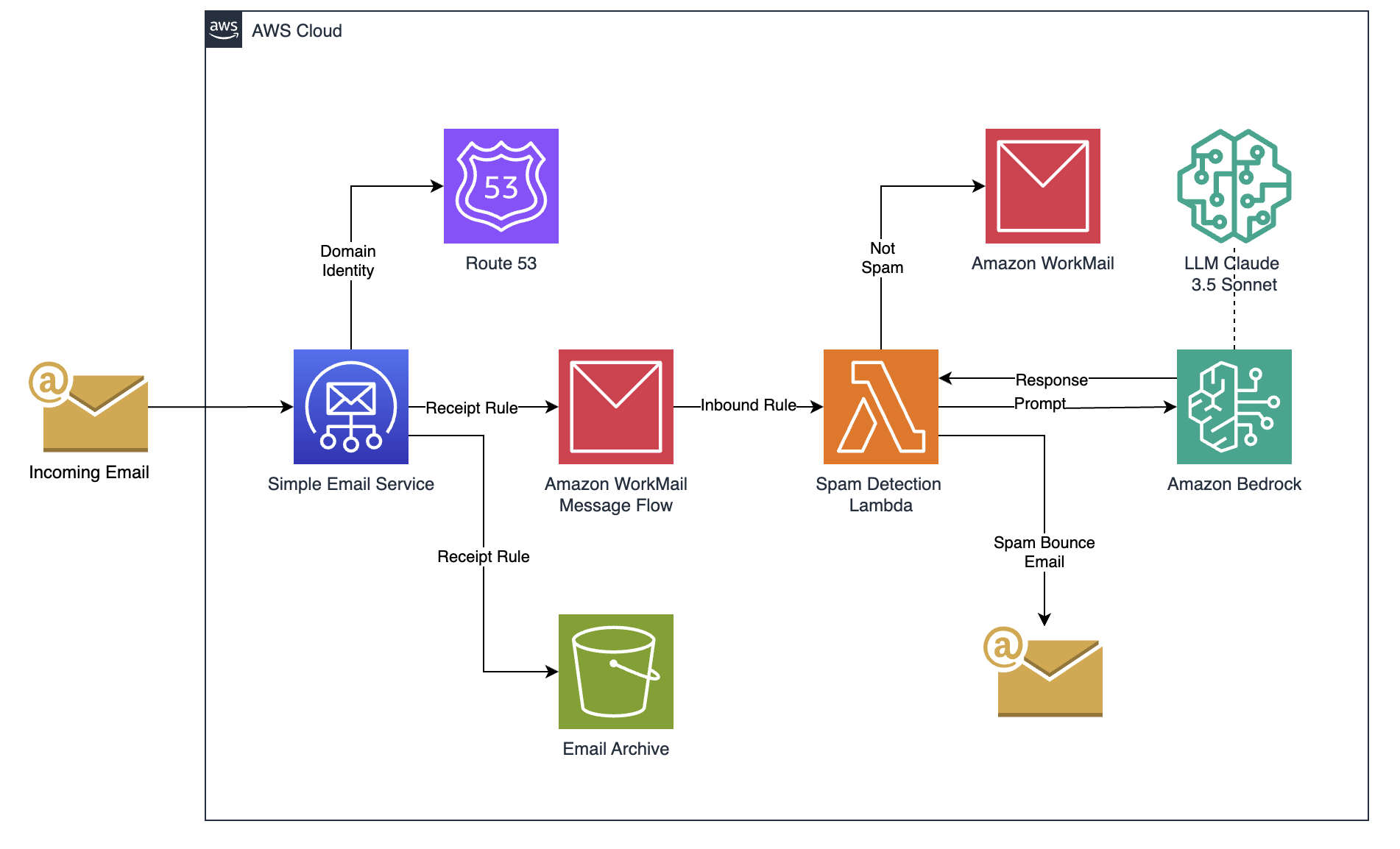
What we need to configure is initial a domain name in Route53, this will allow us to setup both SES and WorkMail. I wont go into detail about this here, it is assumed that you have a domain setup and ready to use.
Configuring SES for delivery to S3
We will first configure SES to deliver all received emails to S3. This is good practice as we will retain all email messages even if they are later discarded by out spam filter solution. We may also in the future want to add a way for a user to retrieve an email that was incorrectly flagged as spam.
As we are configuring email receiving, first we need to create a rule set.
Then within our ruleset we create rules.
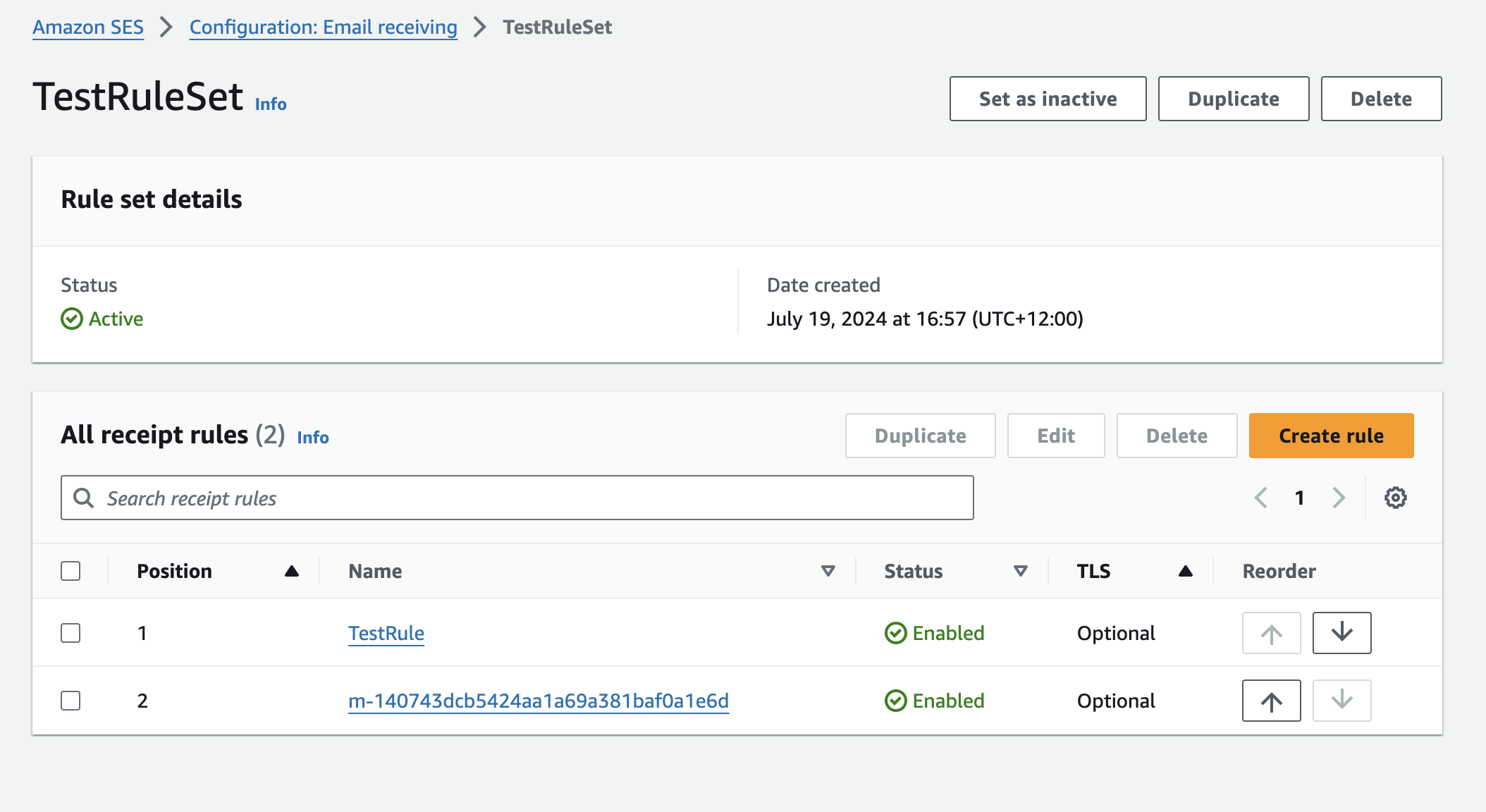
The rule that we want to create is to deliver any received messages to S3.
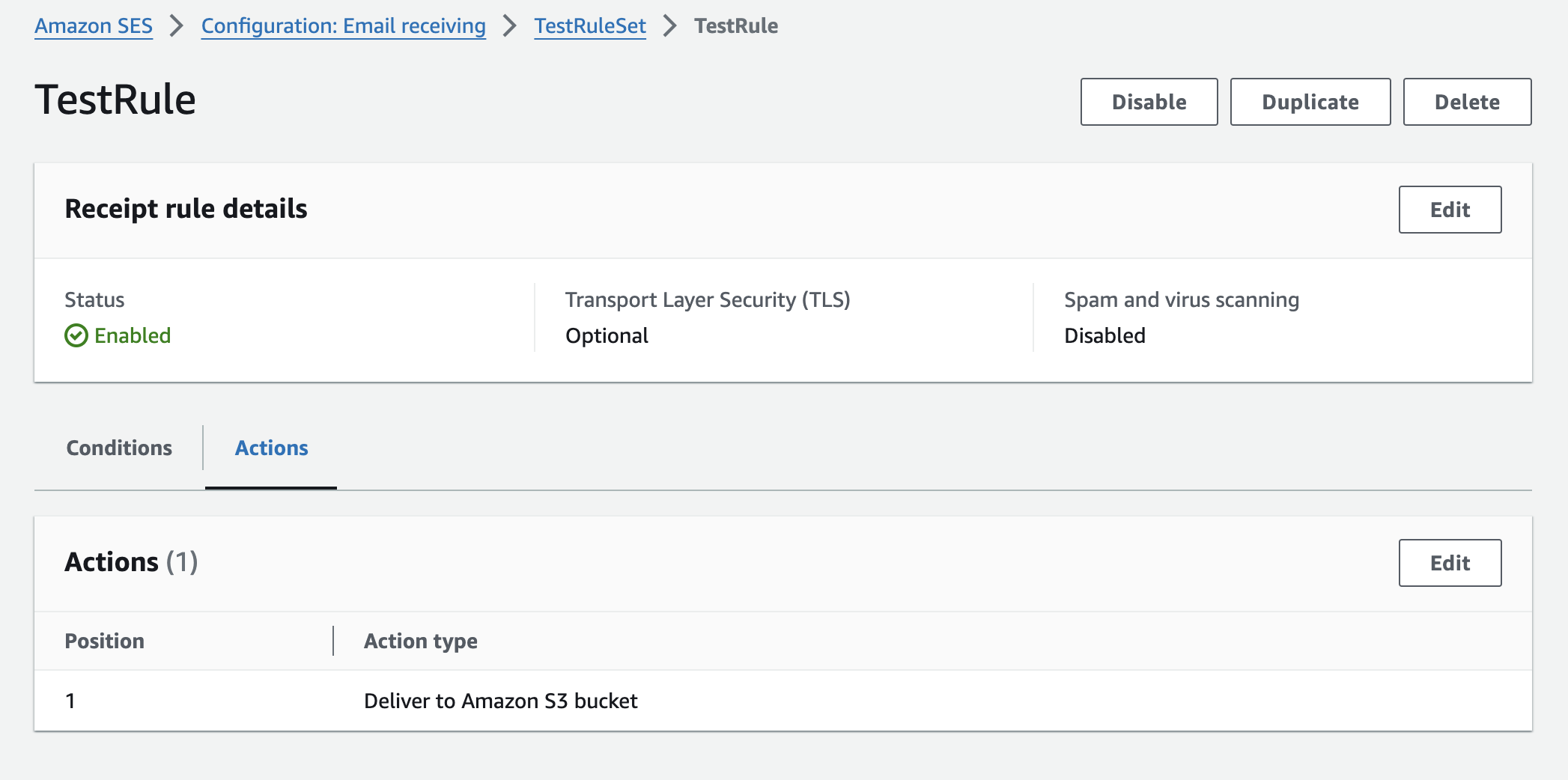
Once this is setup all emails received will now end up in our bucket in S3.
Configuring WorkMail
WorkMail is a managed business email service in AWS. We are going to use this as it is a convenient way to demonstrate this solution. Of course if we were deploying this solution in a production environment we would most likely be integrating with existing email providers. The scope of that change is beyond this blog post, but can be relatively easily implemented.
The initial configuration and setup of WorkMail is very simple, we just need to specify our domain name that was setup in Route53 and click create. This will give us our organisation in WorkMail, and only takes a couple of minutes to provision.
When it is complete we will have access to an awsapps url that we can use to login to our new WorkMail solution.
WorkMail inbound rules
We now need to create an inbound rule in WorkMail. This is so that we can intercept any incoming messages and execute a lambda function to assess if they are spam.
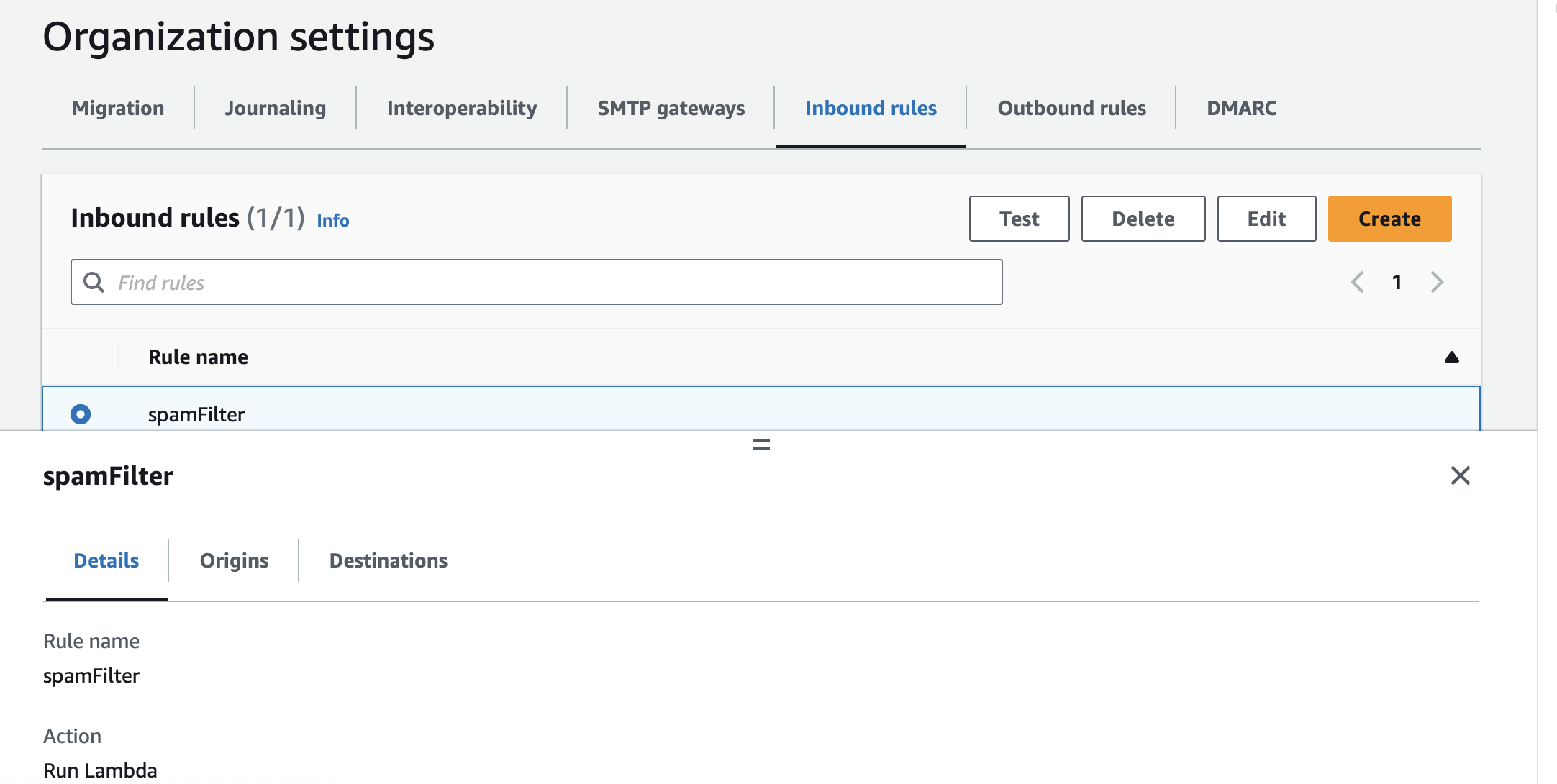
The function that we are going to execute is the spamfilter Lambda function that we have built. This will be executed in a synchronous manner, which means that WorkMail will wait for the Lambda function to return with an action before delivering the email. This allows us to either bounce or deliver the message.
Spam Filter Lambda with Bedrock
Finally in our solution we need the Lambda function that will actually call bedrock and evaluate if the received message is spam. The code for this is below.
import boto3
import json
import email
import os
import logging
logger = logging.getLogger()
logger.setLevel("INFO")
# Initialize Boto3 clients
workmail = boto3.client(service_name='workmailmessageflow', region_name='us-east-1')
bedrock_runtime = boto3.client(service_name='bedrock-runtime', region_name='us-east-1')
def lambda_handler(event, context):
logger.info('Spam filter')
logger.info(event)
# Extract the WorkMail message ID from the event
message_id = event['messageId']
raw_msg = workmail.get_raw_message_content(messageId=message_id)
parsed_msg = email.message_from_bytes(raw_msg['messageContent'].read())
# Convert the parsed email message to a string
email_string = parsed_msg.as_string()
logger.info(email_string)
# Evaluate the email content
is_spam = evaluate_email(email_string)
# Generate the response based on the evaluation result
if is_spam:
logger.info("Email is identified as spam.")
return {
"actions": [
{
"action": {
"type": "BOUNCE",
"parameters": {
"bounceMessage": "Email is undeliverable due to company policy."
}
},
"allRecipients": True
}
]
}
else:
logger.info("Email is not identified as spam.")
return {
"actions": [
{
"action": {
"type": "DEFAULT"
},
"allRecipients": True
}
]
}
# Function to evaluate if an email is spam
def evaluate_email(content):
prompt = (
"Evaluate if this email content is likely to be spam. Provide a boolean response, where 'true' is a spam email. "
"Respond with a SINGLE WORD, either 'true' or 'false'. Do not provide any other information.\n\nThe content is:\n\n"
+ content
)
body = json.dumps({
"prompt": "\n\nHuman:" + prompt + " " + "\n\nAssistant:",
"max_tokens_to_sample": 500,
"temperature": 0.9,
"top_k": 250,
"top_p": 1.0,
"stop_sequences": ["\n\nHuman:"],
"anthropic_version": "bedrock-2023-05-31"
})
response = bedrock_runtime.invoke_model(body=body, modelId="anthropic.claude-3-5-sonnet-20240620-v1:0")
response_body = json.loads(response['body'].read())
# Log the response from Bedrock
logger.info("Bedrock response: %s", response_body)
return "true" in response_body['completion'].lower()
In this function we are going to first retrieve the full content of the email message, this is because we need the full body to assess if this is a spam message. The headers also contain useful information that can help our model decide if this is spam or not as it will be able to recognise things such as DKIM and SPF from the headers.
When we have the full original content of the email, we construct our prompt (the same as we used in the training set) and then then call our high performing model within Bedrock.
The result of this call then decides whether we respond with a bounce action or with a default/deliver action.
To see this running in practice, watch the video at the start of this blog post.
Final thoughts
So this worked really well, even in this example it was reliably blocking and filtering out spam and phishing emails. I was quite surprised by this, as often these GenAI POCs perform reasonably well, but this one performed extremely well. I would say that if this was implemented in a production way it would add a useful layer of security to any company, taking some of the load off the expectation of staff to identify and react to spam and phishing.